

 产业资讯
产业资讯
 动脉网
动脉网  2026-07-04
2026-07-04
 432
432
过去三年,AI虚拟细胞(AIVC)赛道挤满玩家,海量测序数据、数十亿参数模型轮番登场,却始终卡在同一个死胡同里。
一家名为百曜科技的中国团队,踩中了行业最核心的底层矛盾:大语言模型算法架构和真实细胞数据之间的错配。
就在近期,这支团队交出了一条全新解法 —— 全球首个 LLM-JEPA 单细胞世界模型 CellOS 正式对外发布。
依托 3.905 亿条人类单细胞转录组训练而成的 12B 大模型,它首次用双视角 JEPA 架构读懂细胞动态状态,多项核心评测全面刷新行业 SOTA(State-of-the-Art),或将彻底改写制药行业生命科学底层研发范式。
01
生命科学必须另辟蹊径
单细胞测序技术爆发的十年后,随着测序设备源源不断产出细胞数据,加上Transformer架构给了第一代AIVC诞生的可能性。
但大模型领域通行的缩放定律 Scaling Law放在 AI 虚拟细胞赛道,这套经验似乎失灵了。
模型能力没跟上。市面上绝大多数细胞 AI,照搬 Transformer 完形填空训练逻辑:遮挡一段基因,让模型猜答案。
这套机制学的是数据表层规律,本质是 “背诵测序表格”,而非理解细胞。
可真正决定疾病发展、药物反应、细胞分化的,往往是数十个基因叠加的微弱信号。它们表达量不突出,仅凭表层拟合的模型,永远抓不住这些关键变化。
2026 年 6 月《Nature Methods》的一篇量化研究,给行业痛点钉下实锤:用 2220 万细胞训练的模型,仅投入 1%–10% 训练数据,性能就彻底停滞,再增加数据也无法提升效果。
整个行业陷入瓶颈:单纯堆砌数据与参数,弥补不了模型对生物学底层逻辑的缺失。
百曜科技COO杨帆给出结论:传统路线已经走到尽头,生命科学 AI必须换一套底层架构,行业需要另辟蹊径。
02
为细胞创造一个“理解者”
百曜科技此前与行业主流技术路线一致,同样基于 Transformer 架构开展探索,但团队始终希望找到一种能够从底层降低模型对细胞数据偏置与噪声敏感性的方案。
2025 年,公司首次尝试在 Transformer 架构中引入 GNN(图神经网络),希望改善模型对细胞关系的建模能力,但这一方案仍属于局部优化,并未触及问题本质。直到今年年初,百曜科技决定转向一条研发难度更高的技术路线——JEPA(联合嵌入预测架构)。
这条路研发阻力层层叠加,是业内公认的 “险途”。
一方面 JEPA 需要在隐空间对齐两套完全不同的细胞观测维度,另一方面因果损失(causal loss)还要叠加时序约束,双重限制极易造成训练震荡;更棘手的是,细胞基因没有固定文本序列,语言模型成熟的训练约束规则完全无法复用,整套训练逻辑需要从零设计。
“传统模型是让模型复刻输入,我们要做的,是让模型学会预测细胞另一维度的隐藏状态。” 团队解释底层思路。
在Transformer时代,大家常习惯用完形填空的方式训练模型,让它猜出盖住的基因。
这样的方式只会记忆数据,而细胞状态变化是无数微弱基因信号共同作用的结果,单纯记忆无法捕捉动态规律。JEPA的核心价值,是在隐空间跨视角预测细胞表征,剥离测序数据噪声,锁定稳定、真实的生物学特征。
为了落地这套架构,团队设计了独一份的双视角观测体系,也是 CellOS 区别于所有竞品的核心创新:
1、 表达视角(Expression View):清点全部基因表达丰度,还原细胞静态基因构成;
2、 感知视角(Perception View):计算惊奇分数 Surprisal Score,筛选相较于细胞群体,具备高生物学价值的关键信号。
两套视角协同工作:模型先按基因表达量排序全部信息,再由感知视角过滤无效噪声,精准捕捉细胞分化、迁移、病变的关键转折节点。

Expression View和Perception View的协同作用机制
为承载双视角联合建模的巨大算力需求,CellOS采用了Dense-to-MoE 三阶段训练策略,从轻量化密集模型逐步扩容至 12B 混合专家大模型,全程保留模型已学习的生物学知识,避免扩容后性能滑坡。
整套训练数据集规模创下全球公开模型新高:覆盖 47845 组测序样本、3.9 亿单细胞转录组,其中 3.46 亿细胞附带完整精细注释。
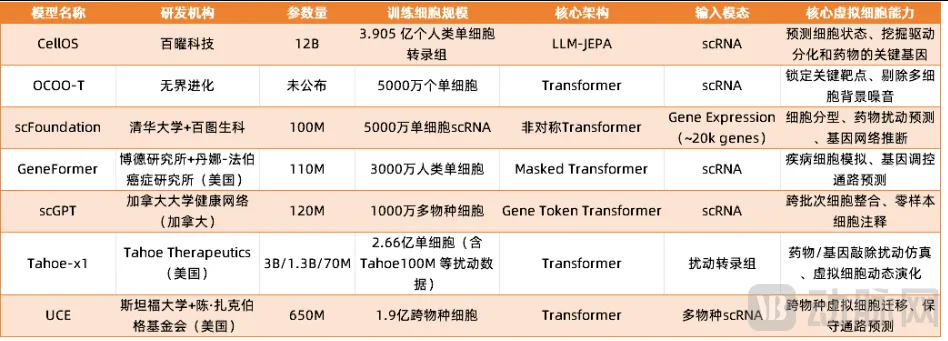
杨帆表示,这是目前全球已公开模型中的最大规模单细胞基础模型,3.905 亿个人类单细胞转录组几乎覆盖所有重要的人类细胞类型。
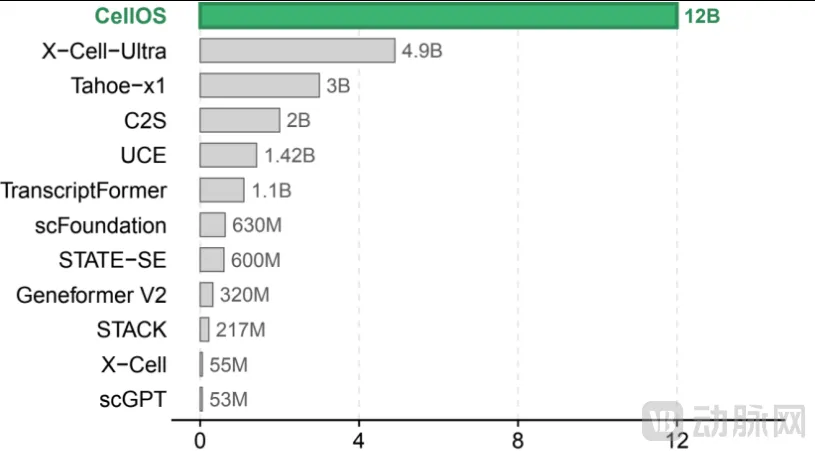
全球主流单细胞模型参数量对比
03
数据全方位碾压主流竞品
路线是否成立,最终要靠对照实验给出答案。
百曜科技用多组横向评测,向我们验证了双视角JEPA架构的绝对优势。
■ 细胞注释与批次整合:兼顾噪声消除与生物信息留存
在统一细胞注释基准测试中,CellOS 生物学保守分数达到 0.792,大幅领先 UCE、scGPT、TranscriptFormer 等主流模型。
面对 T 细胞细分亚群、免疫衰老、iPSC诱导多能干细胞分化这类极难区分细微差异的样本,模型依旧能精准识别细胞状态分层。
批次整合场景下,它平衡了测序技术偏差与原生生物学信号:虽然批次混合指标略低于 STACK,但在减少批次效应的同时,更好保留细胞状态相关的生物学信息,更贴合科研与药企的真实分析需求。
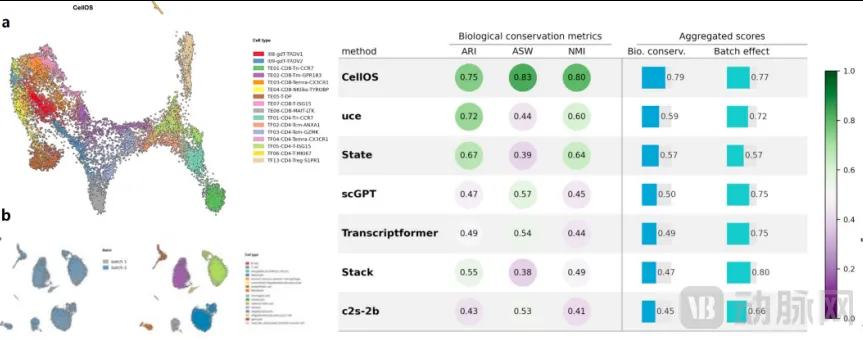
CellOS在细胞注释和整合任务中的评估
■ 药物/基因扰动预测:拉开66%性能差距,行业断层领先
扰动响应预测是AI制药最核心的落地指标,直接决定模型能否提前预判药物对人体细胞的作用效果。
核心指标 Pearson_edist 上,CellOS得分 0.619,是所有参评模型里唯一突破 0.6 阈值的方案;对比此前最优开源模型 TranscriptFormer(0.373),性能提升幅度高达 66%。
散点对照图清晰可见:CellOS 同时拥有极高生物学一致性与扰动保真度,落在行业最优的理想区间内。
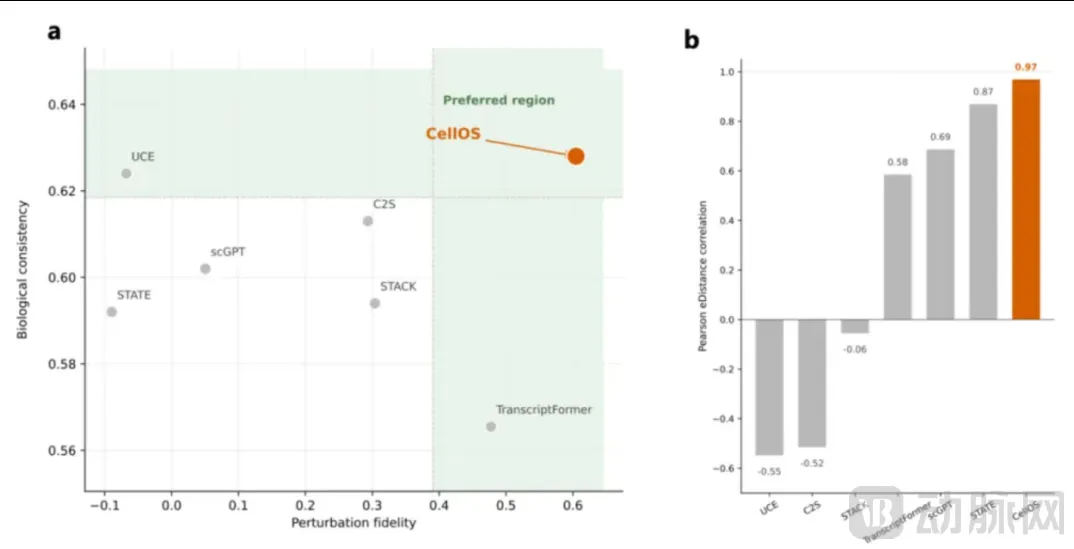
CellOS在药物/基因扰动响应预测与主流模型的横向对比实验
■ 消融实验验证架构正确性:参数越大,性能稳定正向增长
团队做了 0.2B、2B、12B 三组参数规模消融对照,ARI、NMI、ASW 三项聚类指标全部随模型扩容持续上涨,没有出现性能瓶颈。
稳步向上的增长曲线,直接印证JEPA+MoE双视角路线具备可持续缩放能力,不存在传统模型 “数据越多越失效” 的短板。
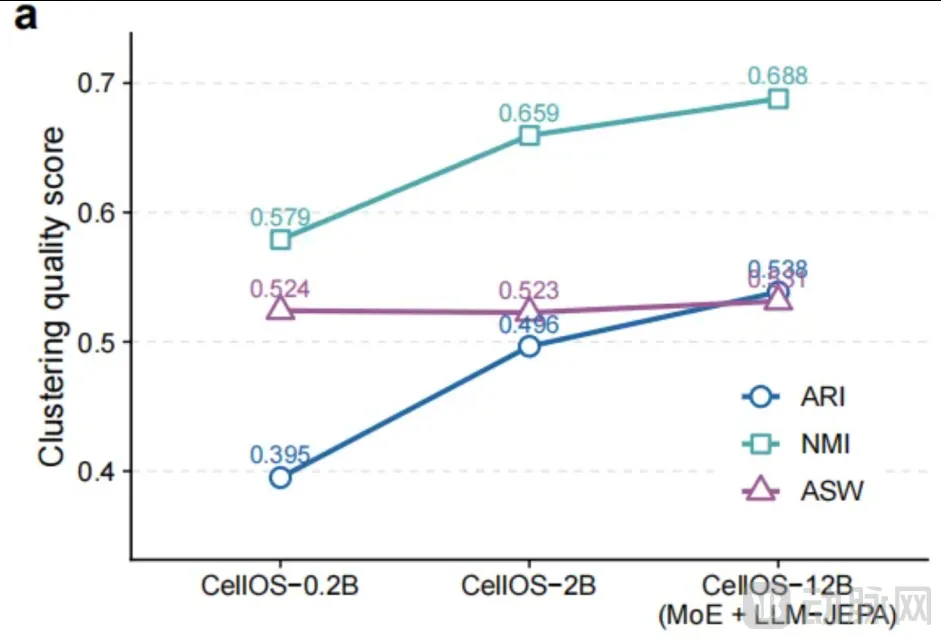
CellOS参数消融实验曲线
“这条清晰向上的性能曲线,是我们研发路上最实在的正向反馈。” 杨帆谈及长达数年的技术攻坚,语气平静却笃定。
全球各AI虚拟细胞基础模型对比(部分)
04
预测细胞,才是AI制药下一轮真正的革命
数年以来,AI对生命科学的改造,始终停留在分子层面:AlphaFold 预测蛋白质结构、生成式AI设计新药分子、自动化工具完成药物初筛。
这些工具大幅压缩新药研发周期。
疾病进展、药物药效释放、人体免疫激活,所有生理变化,本质都是细胞状态持续演化的结果。
研究者已逐渐形成共识:能推动AI制药行业跨越式升级的,从来不是预测单个分子,而是完整模拟细胞动态,推演整套生命系统。
AI虚拟细胞,也因此成为全球生命科学、生物医药、资本圈共同押注的核心赛道。
全球科研院所、创新药企、AI 技术公司,都在围绕 “可模拟、可预测、可定向设计的虚拟细胞” 持续布局。
在此之前,行业始终困在语言模型的固有框架里,无法真正读懂细胞;而 CellOS 的出现,这条全新的 LLM-JEPA 技术路线,似乎给出了一套经过海量数据验证的可行方案。
人类完整预测生命系统的目标,或许不再是遥远的学术设想,而是逐渐清晰的落地路径。
 产业资讯
药事纵横 2026-07-04
460
产业资讯
药事纵横 2026-07-04
460
 产业资讯
医药云端工作室 2026-07-04
458
产业资讯
医药云端工作室 2026-07-04
458
 产业资讯
动脉网 2026-07-04
432
产业资讯
动脉网 2026-07-04
432
 热门资讯
热门资讯 微信公众号
微信公众号